Supports syllables, 5-character sequences, and full words
Precise start-end timing for every fingerspelled unit
Includes detailed demographic and consent metadata for participant-aware modeling and analysis.
Available under terms restricting use to non-commercial academic research
An overview of the basic information and participant information included in this dataset. Provided as CSV files.
Basic information such as the video file path, category, and recording conditions.
| Field Name | Type | Description |
|---|---|---|
| file_name | str | File path of the video sample |
| classes | List[str] | Fingerspelled unit (e.g., `["a"]`, `["ka", "ma", "ku", "ra"]`) |
| category | int | Linguistic unit category: `0=syllable`, `1=sequence`, or `2=word` |
| participant_id | int | Participant identifier (e.g., `18`) |
| recording_date | int | Year and month of recording (e.g., `202403`) |
| fps | int | datasetTable.descriptions.fps |
Demographic information and consent details for participants in the dataset.
| Field Name | Type | Description |
|---|---|---|
| participant_id | int | Unique identifier for the participant |
| age_group | str | participantsTable.descriptions.ageGroup |
| gender | int | Gender of the participant: `male`, `female`, or `unknown` |
| dominant_hand | int | participantsTable.descriptions.dominantHand |
| experience_years | str | participantsTable.descriptions.experienceYears |
| hearing_level | int | Self-reported hearing level: `0` (no issues) to `4` (severe), or `-1` (unknown) |
| face_visibility | int | Face visibility consent: `1=consented`, `0=declined` |
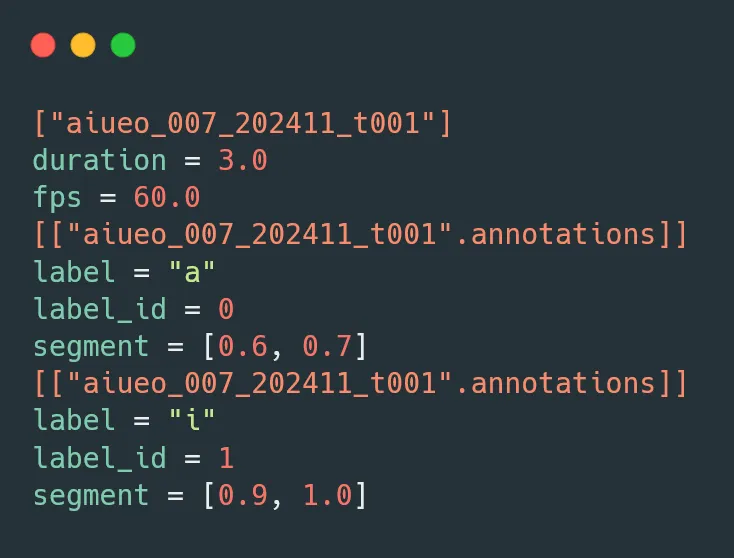
Example temporal annotation showing precise start and end timing for fingerspelling sequences. Each row represents a fingerspelling unit with frame-level accuracy.
@misc{ubmoji2025,
title = {ub-MOJI},
author = {Tamon Kondo and Ryota Murai and Naoto Tsuta and Yousun Kang},
year = {2025},
url = {https://huggingface.co/datasets/kanglabs/ub-MOJI},
publisher = {Hugging Face}
}@inproceedings{Murai2025pointSupervisedJF,
title = {Point-Supervised Japanese Fingerspelling Localization via HR-Pro and Contrastive Learning},
author = {Ryota Murai and Naoto Tsuta and Duk Shin and Yousun Kang},
booktitle = {Proceedings of 2025 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW)},
year = {2025},
}